Parametric Weighted Automata
12 Apr 2019
Joshua Moerman
I moved to Aachen for a post-doc on probabilistic programs (see FRAPPANT). This means that I am learning about new, exciting topics. I will collect notes on this blog, as they may be useful to others. One of the research lines here is that of parametric Markov chains, see for example Parameter Synthesis for Markov Models: Faster Than Ever and references therein.
Parametric Markov chains are just like Markov chains, except that they allow for unspecified, or parametric edges. Instead of a precise probability, these edges will have a formal parameter . To make life a bit easier, I generalise from probabilities in to any value in . So in this post, I talk about parametric weighted finite automata (pWFAs). I will do this for a single parameter , but it all generalises nicely to multiple parameters.
Example Let’s start with an example, before we define pWFAs. The image below defines a pWFA with two states: (initial) and which have the outputs and respectively. We have a single letter in our alphabet. On this letter, the state transitions to with weight and to with weight . State simply transitions to itself with weight . (If there is just a single transition with unit weight, we often simplify the labels in the picture.)
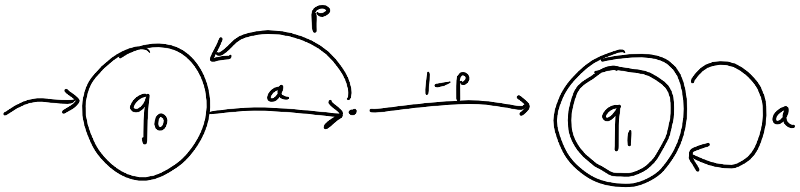
What is the acceptance of – say – the word ? In total there are three paths: , , and with the respective weights , , and . Summing these up, gives an acceptance of . This polynomial can evaluated for any .
Let us fix an alphabet .
Definition A parametric weighted finite automaton, , consists of
- a state space: a finite set ,
- an initial vector: an element ,
- an output function: a map , and
- transition functions: for each we have a map .
Let me explain the notation: is the free -vector space with as a basis. As a set it is , but we think of the elements as formal sums for some values . So the initial vector is really a linear combination of states. In the example above, the initial vector is the state with weight .
In the transition function we see , which is the polynomial ring with indeterminate . (It is also a free vector space, but with a basis ) This allows transitions to use normal weights from , but also polynomials involving . The weight is if there is no -transition from to . The maps can be equivalently defined as . (This is the free -module on .) Going further, it can be equivalently expressed as a -linear map , or even a -linear map. All these manipulations are one-to-one, and I will switch to whatever is useful in the context.
We can do the same for the output map. It is equivalently defined as a linear map , i.e., it is a dual vector .
Example To see why these equivalent characterisations matter, we can compute the example from above:
I have used linearity in many of these steps.
Applications
Why do we bother with all this? We often use Markov chains in model checking, and typically we want to compute things like “what is the probability that something good eventually happens?” But how do we actually obtain a Markov chain in the first place? Some engineer, or domain expert, will design it and has to justify why it models reality. It may be easier to leave some edges unspecified, by using a parameter. Luckily, as we will see, we can still do model checking for parametrised systems. This probability will then, of course, depend on the parameter. So instead of a single value, we obtain a function from the model checker.
I will not be precise in the type of properties we can model check. But I will assume that “good” states are states with an output , and that good states have no outgoing edges (once we are in a good state, we stay there).
Disclaimer You can imagine that for general weighted automata, the outcome may not be a probability (a value in ). We will need all the weights to sum up to , and we need bounds on , etc. We ignore well-definedness in this post and pretend everything is fine.
The probability of reaching a good state is the sum over all paths leading to a good state:
Here I have abbreviated . Let’s keep our fingers crossed and hope that this sum converges. (“Mathematics is wishful thinking” - Wim Veldman.) How can we compute it?
We first generalise this quantity to any state:
Then, by unrolling the transition function once, we see:
where I’ve silently extended linearly.
Now we manipulate this equation, first we write it as a composition (again using linearity to push the sum inwards):
Then, let’s get rid of , and keep the linear functions. We might as well write the composition as a matrix multiplication.
Put things to the other side (here is the identity matrix).
And, finally, transpose and rename:
where the matrix .
So, we see that we can compute , the value that we are interested in, by solving a linear system of equations! Wait, what? Is that really all there is to it? Well, we have cheated a bit, the maps live in a -linear space. This is not a field, and so we cannot expect to just solve this equation. Can we even ask for a map ?
There is a way out: Consider the field of fractions . This is the set of rational functions , where and are polynomials. This is a field which extends the polynomial ring, and so we can solve the equation here. One can solve it with, for example, Guassian elimination, which is very similar to state elimination. (Side note: value iteration will not work in such a field, I believe.)
In the end we find that the probability of eventually ending up in a good state is not a polynomial in . Rather, it is a rational function. I find it cool, that we can derive this with pure linear algebra. Although, this derivation seems easy, of course it hinges on the assumption that a solution exists, a fact which has to be shown separately. Also note that we can do this with as our base field, instead of , in order to do this numerically exact.
Sebastian Junges has implemented such a tool (together with colleagues at RWTH Aachen) and has a nice slide (see s. 41) where he shows that these rational functions can be monstrous expressions. I would like to thank Jip Spel to introduce me to the basics of parametric Markov chains.
Learning
In a subsequent post, I hope to talk a bit about (active) learning of parametric weighted automata. Stay tuned!