PD is not a monad. So What‽
23 Sep 2019
Joshua Moerman
It is a known fact in category theory that monads do not compose in general. However, it is fairly common to combine several types of “effects” (whatever that means) in programming languages. Does the fact that monads don’t compose matter? Is it a bad thing?
I will in particular consider the composition , that is, a nondeterministic choice followed by a probability distribution. This is ubiquitous in computer science: Markov decision procedures (MDPs) are built on this composition, Segala systems use the same construction, and many, many models extend these types.
The fact that is not a monad (in a natural way) is attributed to Gordon Plotkin. And more recently (see the work by Zwart and Marsden or Salamanca and Klin) it has become clear that many monads which are relevant to computer science do not compose neatly. What do such negative results mean? For MDPs, I think it means that we can only talk about the semantics by talking about schedulers. There is no single, easy object which encapsulates all the behaviour of a model.
Let’s try to understand this in terms of programming semantics.
Monads
I will try to avoid the definition of a monad, since you might be opposed to it from the start. Instead, I will argue that we want certain laws to hold when we want to describe semantics.
Suppose we have a programming language with nondeterminism. And suppose that we want to reason about all the behaviour it exhibits.
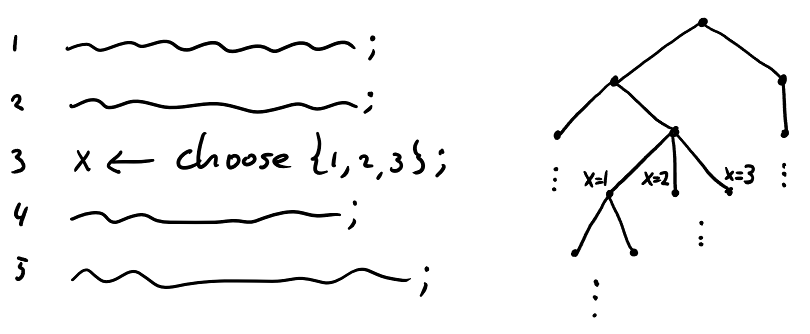
On the left, we see an abstract program. One line tells us that there is a nondeterministic choice with three options. On the right, we unfold all executions of the program as a tree. In principle, this tree contains all behaviours. But it is a bit too precise perhaps: if we want to compare two such programs, we do not care about the depth of this tree, only about the final outputs of the computation.
The obvious thing to do is to flatten the tree. This has an additional advantage that duplicate states are removed. In a picture:

We can do this at every step. So in the end, we obtain all behaviours of the program simply as a set of outputs. We can do this with other types of programs too. For instance, in probabilistic programming, we can maintain a probability distribution of states. The flattening operation will then take a weighted sum of such distributions, resulting in a single distribution.
What properties do we expect from such a “flattening operation?” Let’s consider a program and let’s put two statements between brackets, making it a single statement. (You can tell that I’m a theoretician, since all statements are just lines.)
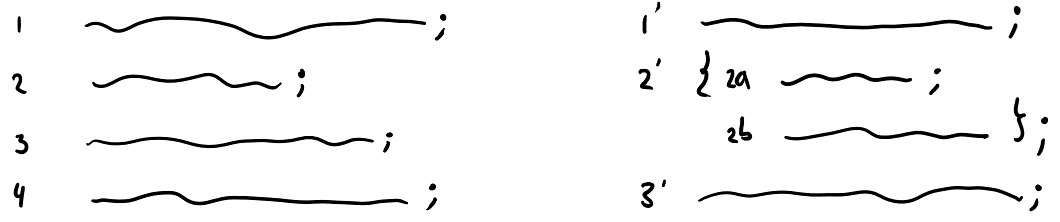
The composed statement is like a subprogram. On the left we flatten as follows: We run line 2 on every state produced by line 1, then flatten. With all resulting states, we run line 3, then flatten. On the right, it’s different: On every state produced by line 1’, we run line 2’ which consists of two steps, run 2a and on each output 2b, then flatten. Note that this flattening is now for a fixed output of line 1’. After the flattening in the subprogram, we collect all those results on all outputs of line 1’ and then flatten the whole thing.
Surely, this does not matter for the final output (i.e. all behaviour) of the program. Let’s call this property associativity.
Another property we expect is that the two programs below are the same. This we could call unitality.

Both these properties are like sanity conditions. Whatever our flattening semantics, these should hold. And indeed, they hold in nondeterministic and probabilistic programming. (The two conditions are a handwavy description of the monad laws. I believe that if you agree with the intuition, then you will also agree with the formal monad laws.)
What about MDPs?
Now we want to model nondeterminism followed by probabilities. Programs and their execution tree look like this:

The nondeterminism is drawn as before, and the probabilistic choice is drawn as a connected thingy (imitating a continuous choice, although discrete probability distributions are fine too).
The fact that is not a monad means this: We cannot flatten the tree to a single level, while adhering to the sanity conditions.
So what?
It entails that we cannot compare programs by just looking at a final set/distribution of outputs. Said differently: It matters how choices are made during execution. However, we can still work with these structures (as people have been successfully doing for a long time). For MDPs and Segala systems, we can introduce the notion of a scheduler. A scheduler resolves the nondeterminism, so that we can talk about just a probability distribution (which then can be flattened). This is also reflected in logics such as PCTL. In that logic we can talk, existentially or universally, about schedulers.
Can schedulers distinguish programs based on the depth of the execution tree? Absolutely. But there are two important types of schedulers which do not: schedulers which minimises some goal functions and the one which maximises. These are most often used in practice. In model checking of MDPs, we often only compute minimal and maximal probabilities. Also in PCTL, we only talk about bounds on probabilities. In semantics such as QSL, the calculus minimises “post-expectations.”
(Results from van Heerdt et al. and Bonchi et al. tell us that these are very important schedulers. My understanding is that these are actually the only natural ones. But one can compose them, which gives something similar to PCTL. I’m not completely sure on this, but that’s my reading of it.)
So is it bad?
No, I guess? I do think that having a monad makes life easier: you can flatten multiple steps in a computation, and just compare results. We cannot do that for , and so grasping all behaviours of such a program is harder, we have to resort to schedulers. Monads are nice and all, but not having one is not the end of the world either. I’m sure there is more to it, but this post reflects my current understanding on the topic.