Residual probabilistic automata are not closed under convex sums
9 Jan 2020
Joshua Moerman
Just a quick counterexample. Let’s fix a finite set as our alphabet.
Definition A probabilistic automaton (PA), , consists of a finite state space ; a distribution of initial states ; an acceptance function ; and a probabilistic transition function for each .
This is roughly the definition of Rabin automata. Via the usual definitions, the semantics of a state is given as . The value denotes the probability of accepting starting in state . The language of the automaton, , is then given by the initial states .
Any function is called a language. Given a word , we define the derivative language as
Definition An automaton is residual if for all states , there is a word such that .
This definition comes from learning theory. There, all information about the automaton has to be inferred from the values form some words . This is challenging, as nothing is known about the states. Residuality helps: It tells us that will be observable at some point. (Namely after the word .) It means that we can recover all states if we have enough data. Residual PA can be learned efficiently (in the limit), but we do not have such results for general PA.
The class of languages accepted by a residual PA is a strict subclass of languages accepted by PA. But it’s strictly bigger than the class accepted by deterministic PA. The subclass can be characterised as follows.
Theorem (Denis & Esposito) Given a language , TFAE:
-
can be accepted by a residual PA;
-
There is a finite subset which generates by convex sums.
Here is the set of all derivatives. (I use a reactive version of PA, whereas Denis and Esposito use a generative model. The differences are inessential.) To get an intuition for the above theorem, compare it to the Myhill-Nerode theorem. The (proof of the) above theorem also gives a canonical construction.
Closed under convex sums?
Given two languages , we can consider their convex sum . The class of languages accepted by PA is closed under this operation. The usual union construction for NFA does the trick.
What about residual PA? It turns out those languages are not closed under convex sums. I’ll give an example. First, consider the following PA on a one-letter alphabet.
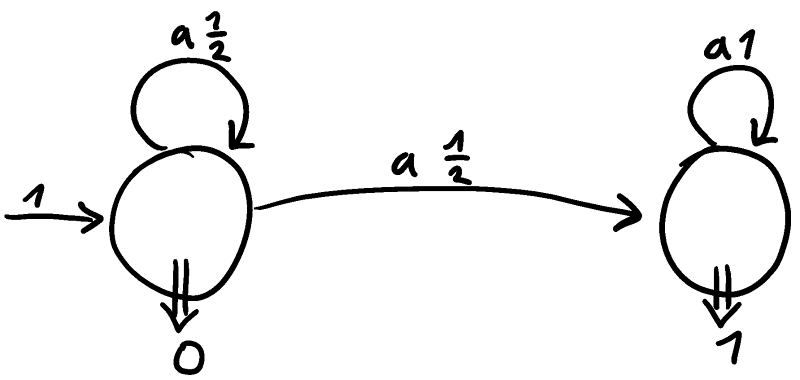
This automaton is not residual. We can make any automaton residual by adding so-called “anchors.” This drastically changes the language (and alphabet), though. By doing this, we get the automaton with two letters.
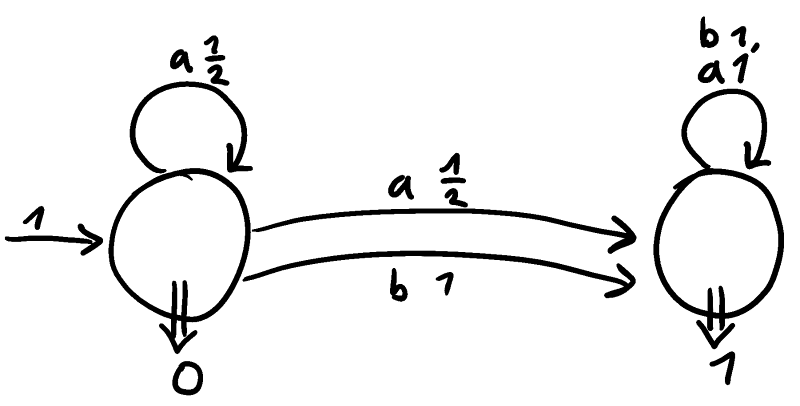
This automaton is residual. Consider the same automaton, but swap and , call it . The language cannot be accepted by a residual automaton!
To see this, consider the derivatives , , , and . (Note that whenever contains at least one and one .) The problem is the that approach a limit, but this limit itself is not a derivative. There is no finite set of derivatives which generate all . So by the theorem, there is no residual PA for this langauge.
I don’t consider this a problem. Closure properties simply do not play an important role in learning theory. For instance, the must-read paper by Denis and Esposito develop the theory of residual PA in depth, providing many results, such as canonical minimal automata, decision procedures, and complexity results. However, they do not even mention closure under convex sums.
Together with Matteo Sammartino, we have some work in progress on residual nominal automata. It mirrors the situation of probabilistic automata closely, with a bit more undecidability sprinkled around. I think it’s a nice topic, and it’s good to understand residuality and its use in learning in different contexts.