L* Learning of pWFAs
3 May 2019
Joshua Moerman
In my previous post, I defined parametric weighted automata. These are WFAs where we allow a parameter (or multiple parameters) on transitions. For a given word, the acceptance of that word is given by a polynomial in , instead of a single real value.
Can we use L* to learn (the structure of) such automata? It is not hard to see that the answer is positive. The trick is to generalise the definition of a pWFA as follows.
Definition A generalised pWFA consists of
- a state space ,
- an initial vector ,
- an output function , and
- transition functions for each .
I say “generalised pWFA”, but it really is nothing more than a normal WFA over the extended field . We now have the following inclusion of automata types:
To learn a pWFA, we consider it in the bigger class of WFAs (over the bigger field). Then we can use the usual L* algorithm for weighted automata, as it works over any field. (See Balle and Mohri for an overview, or Jacobs and Silva for an example run of the algorithm.)
Example We consider the alphabet and wish to learn the following 2-state pWFA:
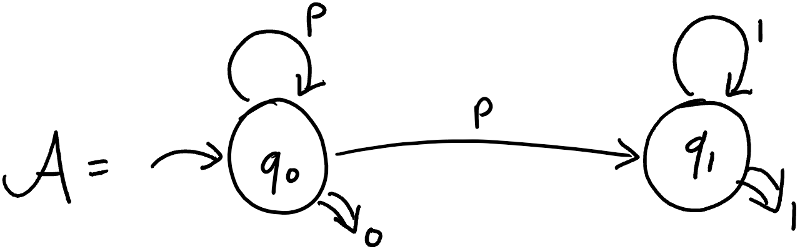
I have omitted the s, as it’s the only letter in our alphabet. The L* algorithm may, at some point, have observed the following data:
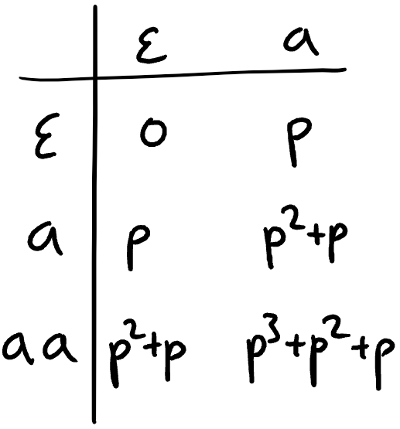
(This table is filled with membership queries: we assume those return the exact polynomials.) We find that this table is closed. In particular, the row of is a linear combination:
This means that we can construct the following hypothesis:
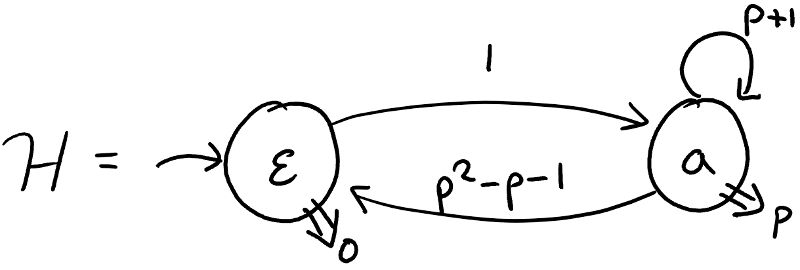
This is a correct hypothesis, in that it is language equivalent to the target automaton. This is not immediately obvious, but one can (and should) check. However, the result may be a bit unsatisfactory. Let’s discuss the problems.
Problem 1 The output map uses a polynomial in state , while all the original outputs are real values.
Problem 2 There is a transition of degree two (from state to ), while all transitions in the original automaton have degree at most one.
There is a third potential problem. It is not shown in the example above, but it may happen with the L* learning algorithm.
Problem 3 There may be transitions with a weight .
All these problems arise because we generalised to weighted automata over . The learning algorithm (which needs a field to work) can and will use such weights freely.
On one hand, the generalisation is no big deal for learning, as membership and equivalence are still decidable. However, when we want to analyse the hypothesis, for example by model checking, the tools may not accept the generalised format. Some tools require transitions to be linear, outputs to be real values, etc.
Question Can we renormalise the weights to solve the these problems? That is, can we find outputs in and transitions weights in , possibly linear, by shifting some weights around?
All this is somewhat reminiscent of the problem of learning probabilistic automata. We have the following automata types:
We can use L* to learn automata in DFA or WFA without any problem. Unfortunately, we cannot (yet?) learn PAs. This is a consequence of the fact that converting a WFA into a non-negative WFA is computationally very hard. (I should add a reference here. In the meantime, please enjoy this excellent paper by Denis and Esposito.)
So in this case, the generalisation to WFA makes learning PAs possible. But you end up with an automaton of the wrong type. You can find more on learning PAs on Nathanaël Fijalkow’s blog Games Automata Play.